

一、简介
- • AnyCrawl 提供高性能网页数据爬取,其功能专为 LLM 集成和数据处理而设计
- • 支持利用搜索引擎直接查询获取结果内容,类似 searxng
- • 提供开发者友好的API,支持动态内容抓取,并输出结构化数据,如markdown、网站元信息等
- • 支持Docker一键快速部署,资源占用相对较低
- • 项目开源,地址参考:https://github.com/any4ai/AnyCrawl
- • 该项目大概工作原理如下图所示:
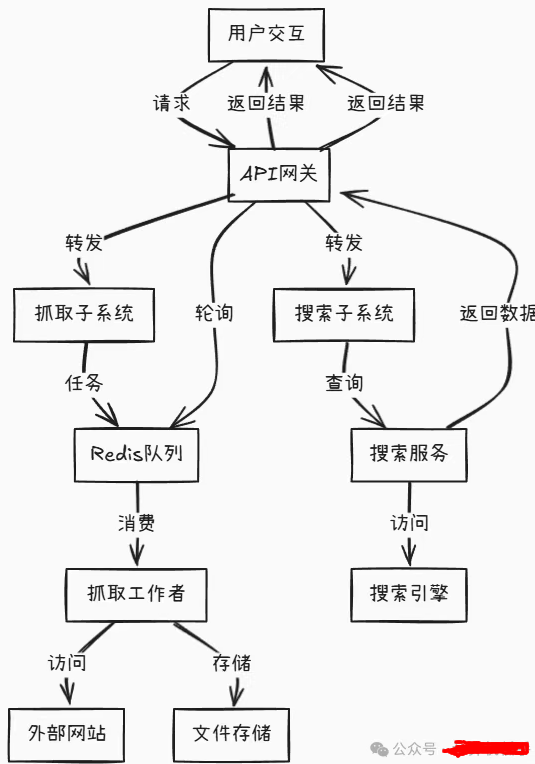
二、安装
- • 提前准备好Docker、docker-compose软件环境
- • 新建docker-compose.yml配置文件,内容如下(确保8080不被占用,如已被占用,请修改下面的端口映射配置):
name: anycrawl
x-common-service: &common-service
networks:
- anycrawl-network
volumes:
- ./storage:/usr/src/app/storage
x-common-env: &common-env
NODE_ENV: ${NODE_ENV:-production}
ANYCRAWL_HEADLESS: ${ANYCRAWL_HEADLESS:-true}
ANYCRAWL_PROXY_URL: ${ANYCRAWL_PROXY_URL:-}
ANYCRAWL_IGNORE_SSL_ERROR: ${ANYCRAWL_IGNORE_SSL_ERROR:-true}
ANYCRAWL_REDIS_URL: ${ANYCRAWL_REDIS_URL:-redis://redis:6379}
ANYCRAWL_API_PORT: ${ANYCRAWL_API_PORT:-8080}
ANYCRAWL_API_AUTH_ENABLED: ${ANYCRAWL_API_AUTH_ENABLED:-false}
ANYCRAWL_API_DB_TYPE: "sqlite"
ANYCRAWL_API_DB_CONNECTION: "/usr/src/app/db/database.db"
services:
api:
<<: *common-service
image: ghcr.io/any4ai/anycrawl-api
environment:
<<: *common-env
ports:
- "8080:8080"
volumes:
- ./storage:/usr/src/app/storage
- ./db:/usr/src/app/db
depends_on:
- redis
scrape-puppeteer:
<<: *common-service
image: ghcr.io/any4ai/anycrawl-scrape-puppeteer
environment:
<<: *common-env
depends_on:
- redis
scrape-playwright:
<<: *common-service
image: ghcr.io/any4ai/anycrawl-scrape-playwright
environment:
<<: *common-env
depends_on:
- redis
scrape-cheerio:
<<: *common-service
image: ghcr.io/any4ai/anycrawl-scrape-cheerio
environment:
<<: *common-env
depends_on:
- redis
redis:
image: redis:7-alpine
volumes:
- redis-data:/data
networks:
- anycrawl-network
command: redis-server --appendonly yes
volumes:
redis-data:
networks:
anycrawl-network:
driver: bridge一键启动,执行如下命令
docker-compose up -d查看所有服务是否正常运行

三、使用示例
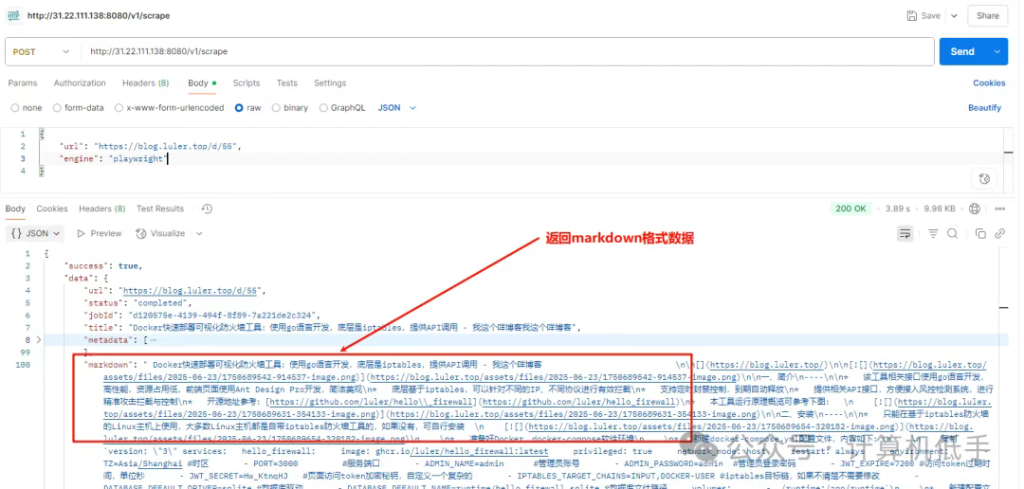
1. 爬取一篇文章内容,返回 LLM 友好的markdown内容
• 爬取网页接口:http://127.0.0.1:8080/v1/scrape
• 请求方法:POST
• 请求参数:
{
"url": "https://blog.luler.top/d/55", //网页链接
"engine": "playwright", //支持多种引擎,cheerio、puppeteer 、playwright,cheerio适合静态网页,puppeteer 、playwright适合动态网页
"proxy": "http://127.0.0.1:10808" //支持设置代理,非必填
}Postman请求示例截图如下:
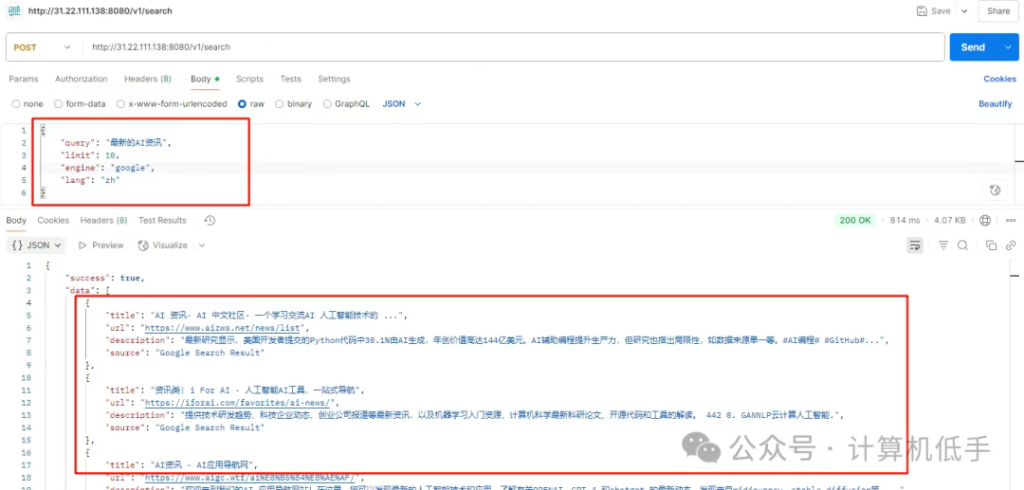
2.获取搜索引擎结果 (SERP)
• 爬取网页接口:http://127.0.0.1:8080/v1/search
• 请求方法:POST
• 请求参数:
{
"query":"最新的AI资讯",//要搜索查询的内容
"pages":1,//分页
"limit":10,//限制返回数量
"engine":"google",//指定搜索引擎,好像目前只有google
"lang":"zh"//指定查询的语言,例如en、zh、all
}Postman请求示例截图如下:
四、总结
- • 安装使用都挺方便的,性能较高,总体感觉比 Firecrawl 优雅好用
- • 提供简易的搜索查询服务,可以获取到一些实时讯息,可以作为 LLM 联网能力组件